Vanna 介绍
欠了很久的分享,今天晚上终于还了。群友一直催自然语言转SQL都有哪些方案,我说那我讲讲 Vanna 吧。而且 Vanna 也跟 RAG 有剪不断、理还乱的关系。
大家好,我是九析,九析带你轻松完爆。
Vanna 是一款开源 text2sql AI 工具,专注将自然语言转为 SQL 语句,从而简化数据库查询。

但通过探索,我意识到 Vanna 远不止一个文本转 SQL 工具简单。至于为什么,我们后面慢慢说。
目前 Vanna 在 Github 已收获 18K 星标。
02Vanna 使用场景
Vanna 的使用场景主要有:
- 不懂数据库查询语言的数据分析师和业务人员也可以查询数据库
- 企业构建内部智能数据查询助手
- 开发者可以快速搭建自然语言数据库接口
03Vanna 特点
Vanna 特点总结下来有以下五个:
- 自然语言查询转 SQL用户通过自然语言提问,Vanna 会自动转成 SQL 查询,并可直接在数据库上执行,返回查询结果和可视化图表
- 基于 RAG 技术Vanna 利用 RAG 框架,将数据库元数据、业务文档以及已有的 SQL 查询等信息嵌入进向量数据库,通过 LLM 进行语义检索和生成,保证生成 SQL 的准确性和上下文相关性
- 可微调支持多种 LLM、向量数据库和 SQL 数据库,用户可以针对数据库进行微调,这是一大优势。
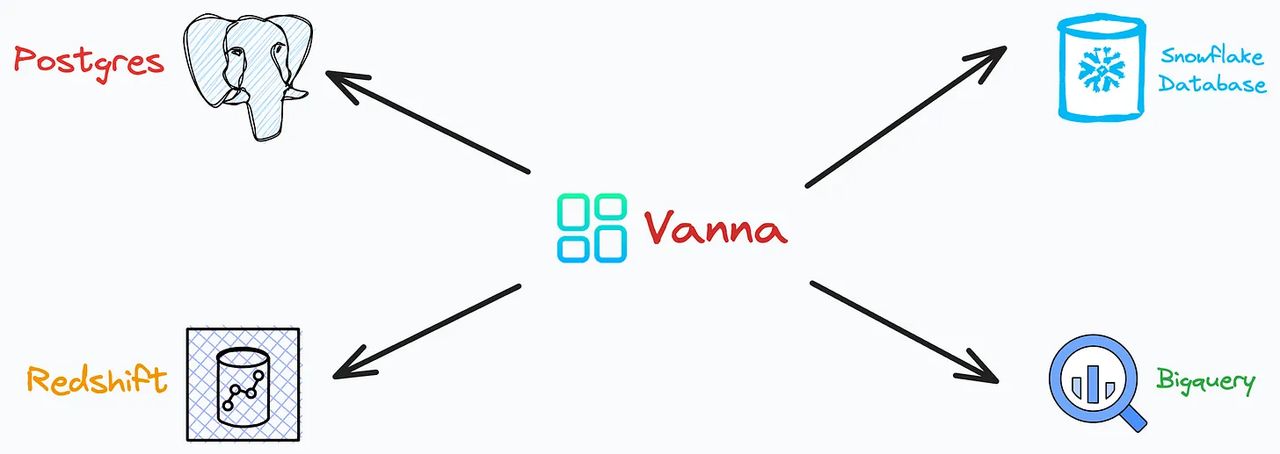
- 开源且免费Vanna 采用 MIT 许可开源,提供 Python 包和丰富文档,适合开发者和企业使用
- 安全私密SQL 查询在本地数据库执行,数据不会泄露给外部模型,保障数据安全
此外,Vanna 会持续适应新数据。因此,你用得越多,它就表现得越好。
04Vanna 输出
当用户用文本提示查询数据库,Vanna 会产生四个输出:
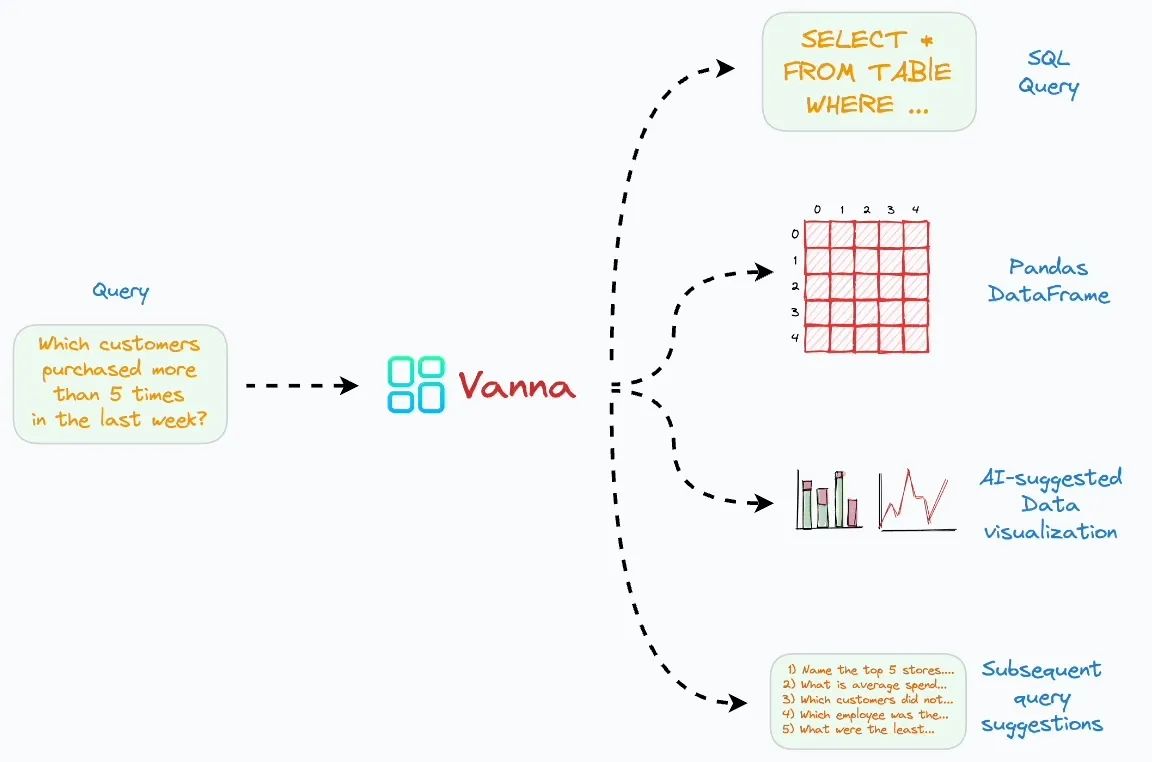
- 自然语言查询语句转化的 SQL 语句
- SQL 语句执行结果,以 Pandas DataFrame 表示(简单说明: DataFrame 是一种数据结构,类似 excel 表格)
- 查询结果的可视化表示(比如柱状图、折线图等)
- 其他相关问题推荐(简单理解就是:猜你想查)
Vanna 屌不屌?不对,应该说 Amazing!
05Vanna 工作流程
Vanna 的工作流程主要分为两个阶段:
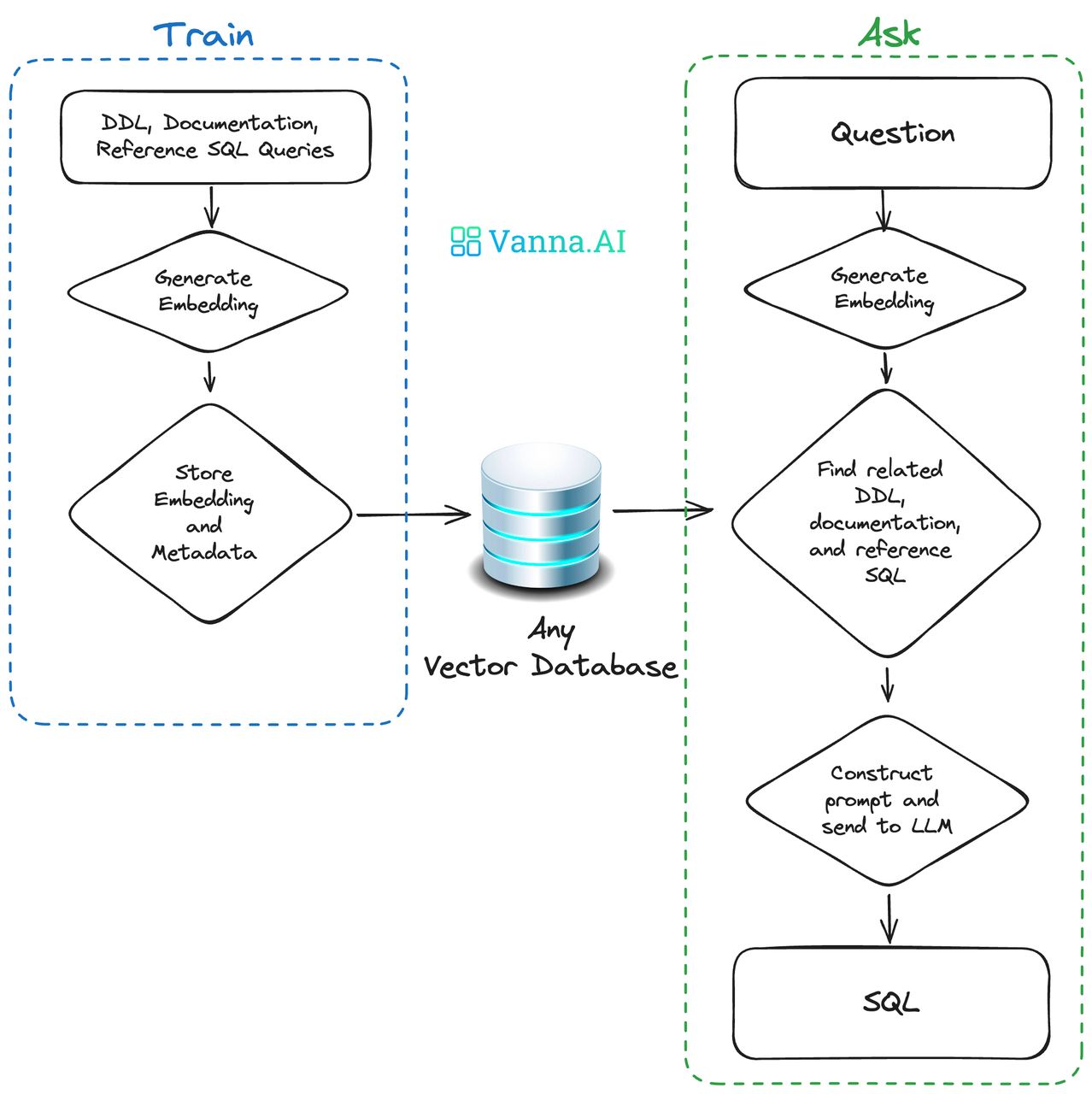
- 训练模型阶段:训练一个 RAG 模型。通过将数据库元数据(DDL)、业务文档和已有 SQL ,通过 train() 接口,训练一个 RAG 模型。
- 提问模型阶段:用户用自然语言提出问题,Vanna 通过在 RAG 模型中进行语义检索,再通过大模型生成对应 SQL 语句,并传给数据库引擎执行
最终执行结果通过多种前端展示方式,方便用户查看和分析数据。
06Vanna 快速开始
6.1 创建虚拟环境
使用 conda 创建虚拟环境,目的是防止与其他项目相互干扰,起到环境隔离的目的。
- conda create -n vanna python=3.11
6.2 激活虚拟环境
使用 conda activate 激活虚拟环境。
6.3 创建工作目录
使用 mkdir 指令创建工作目录 vanna。
6.4 安装 Vanna
使用 pip 指令安装 vanna,指令执行成功,就在本地成功安装了 Vanna,是不是有点简单?
6.5 免费获取 Vanna 密钥
本地安装 Vanna 成功后,就可以配置自己的模型和数据库了。但为了快速上手 Vanna ,我们可以先在 Vanna 官方在线体验自然语言检索数据库的能力。体验前,需要到官网申请 Vanna 密钥。免费获取密钥的网址如下:https://vanna.ai/account/login?next=/account/profile
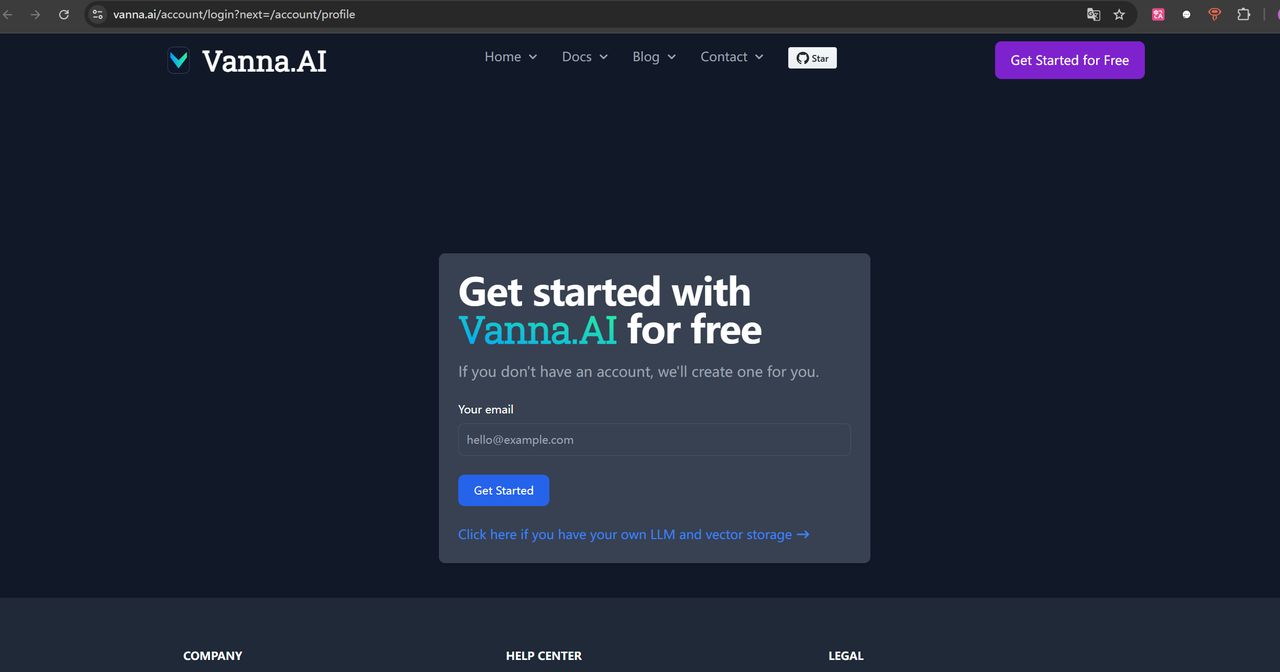
你需要提供自己的邮箱进行申请,申请成功后,进入到导航页面,就可以看到你自己的 api_key。
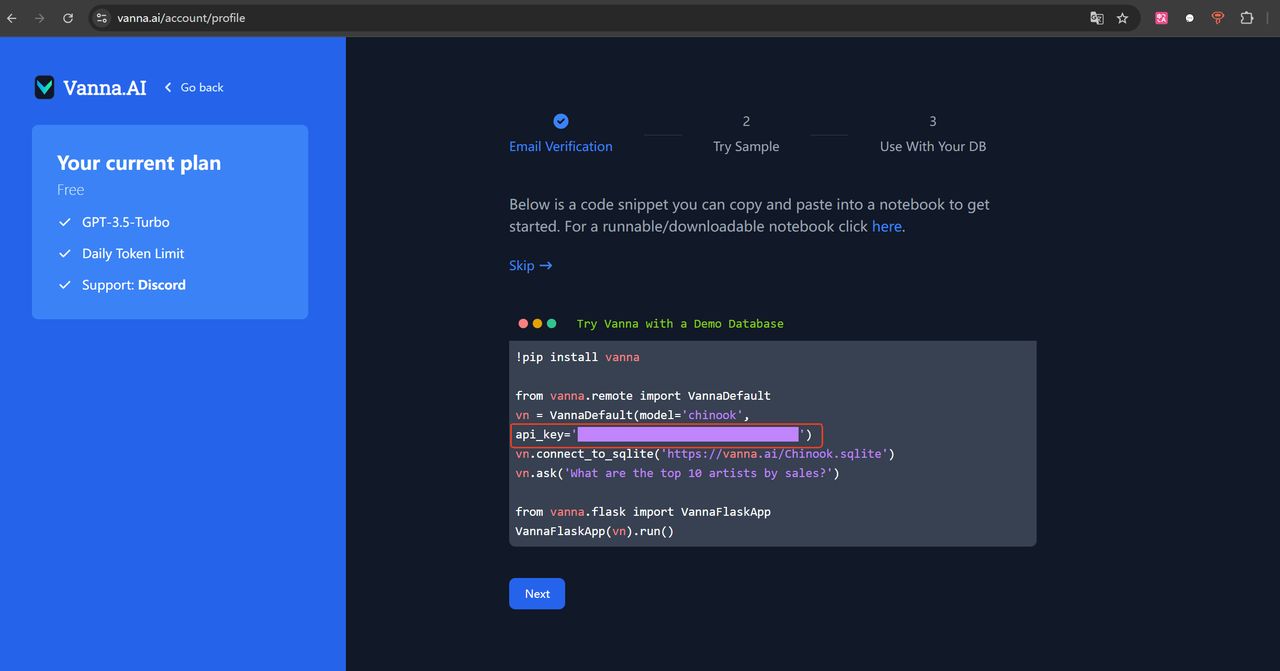
请妥善保管好这个 API_KEY,因为后面我们写代码的时候需要用到。
6.6 选择模型
从前面的 Vanna 工作流程可知,在查询数据库之前,必须使用一个模型。这个模型可以是:
- 一个你已经微调过的现有模型
- 一个你打算进行训练的新模型
- 一个公开发布的模型
我们这里使用的是 Vanna 在线提供的 “chinook” 模型,该模型已经在音乐销售数据集上进行了微调。
6.7 选择数据库
官方不仅给我们准备好了已微调好的模型,还贴心提供了 SQLite 文件数据库。SQLite 是一个轻量级的嵌入式关系型数据库管理系统,它被设计为一个自包含的、无服务器的、零配置的数据库引擎,基于文件系统。
优点:简单、高效
缺点:并发、大数据量支持不好
官方案例提供的是销售业务,数据库的设计如下:
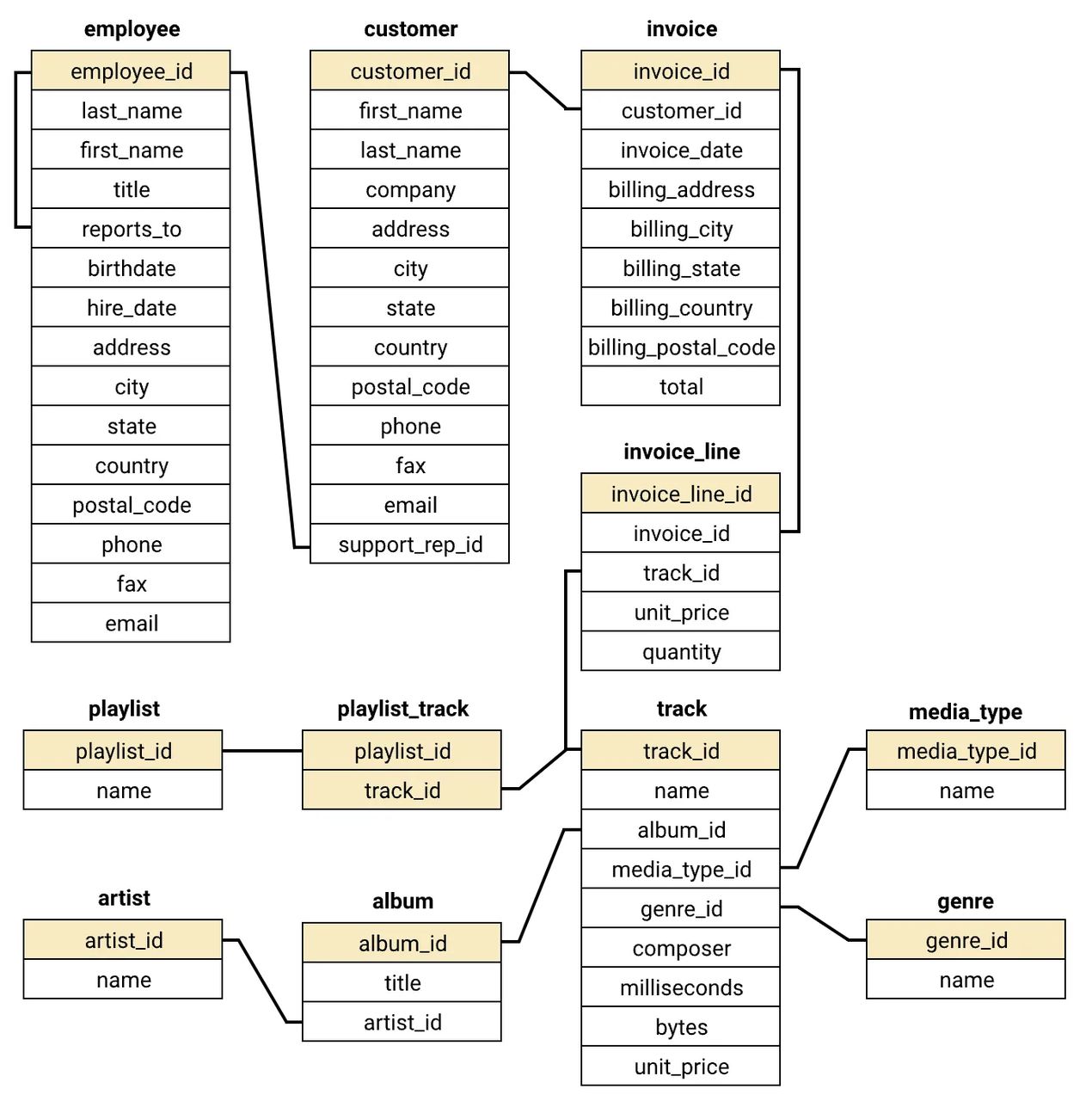
6.8 查询数据库
接下面开始代码编写环节,我们使用 Vanna 提供的 ask 接口,通过自然语言进行查询。
最终完整代码如下:
- from vanna.remote import VannaDefault
- vn = VannaDefault(model='chinook', api_key='391aaac8c63549cb8d440a24c824fa90')
- vn.connect_to_sqlite('https://vanna.ai/Chinook.sqlite')
- vn.ask('What are the top 10 artists by sales?')
- from vanna.flask import VannaFlaskApp
- VannaFlaskApp(vn).run()

执行结果分为三部分:
- 产生详细的 SQL 提示词
- 大模型产生的 SQL 执行语句
- 查询数据库产生的最终结果
Done! 完成!如果需要,你也可以完全训练自己本地模型。我们下节课会具体讲述实现过程。
07相关资料
来自圈子: 浙江理工大学AIGC |